仕事や研究で参考になる資料を探そうと、ネットサーフィンしてやっとの思いで見つけたファイルがコピペできないPDF(PDF画像)だったらがっかりですよね…特に昔の文章では、文章を画像としてPDF化していることが多いので、困ってしまうことが良くあります。僕も大学院生の時は散々苦労させられました…そう、オンラインでOCR機能を使えることを知るまではね。
というわけで、今回はPDF画像に変換した平家物語の冒頭の再テキストしながら、実践的に解説をしていきたいと思います。
目次
Free Online OCRの使い方
今回は次のようなPDFファイル(画像)を用いて、解説を進めていきたいと思います。PDFファイルをダウンロードしてから進めていただければ、より簡単に手順を理解できると思いますので、気になる方はご活用くださいね。

まず、free Online OCRの公式サイトへと移動します。するとこのような画面が現れます。
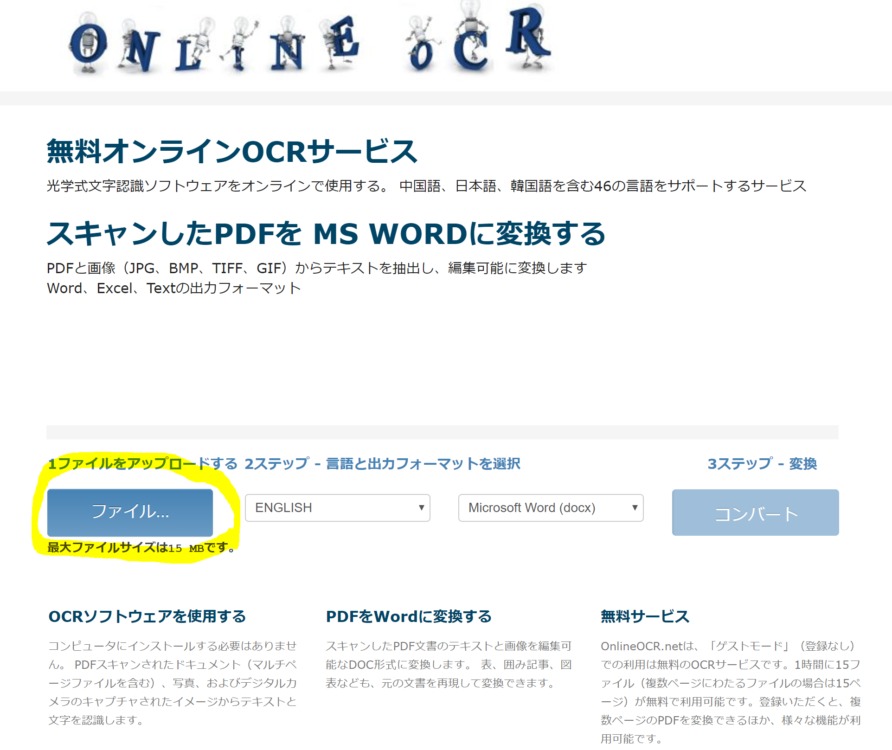
黄色の蛍光ペンで囲まれている部分をクリックし、変換したいファイルを選択します。そして、「English」となっている言語選択のタブを選択して、「Japanese」に変更します。これで、日本語を読み取れるようにします。また、「Microsoft Word(docx)」となっている出力フォーマット選択のタブはそのままで構いません。
これで下準備は完成です。あとは、「コンバート」ボタンをクリックするだけで変換されます。変換後のwordファイルを確認すると、こんな感じになっていました。やはり、文字認識機能を使用しているので、所々に変換ミスが見受けられます。具体例としては、「祇」が「砥」、「、」が「❛」にあげられます。しかし、実用性には十分に耐えうるレベルだと思います。

Free Online OCRの注意点
- 最大ファイルサイズは15MBとなっています。
最大サイズを超えている場合は、PDFファイルを分割してから変換しましょう。 - 一時間当たり、15ページ分の変換が限度です。
まぁ、一時間当たり15ページ分のPDFファイルを変換できるので、無料版でも十分実用に耐えうると思います。
Convertioの使い方
次に、Convertioを使用して、平家物語冒頭のPDF画像ファイルをwordファイルへと変換します。
まずは、赤塗りのところから、どこからデータを引っ張ってくるかを選択することが出来ます。ちなみに、左から順に「コンピューター」・「ドロップボックス」・「google drive」・「URL」となっていますよ。
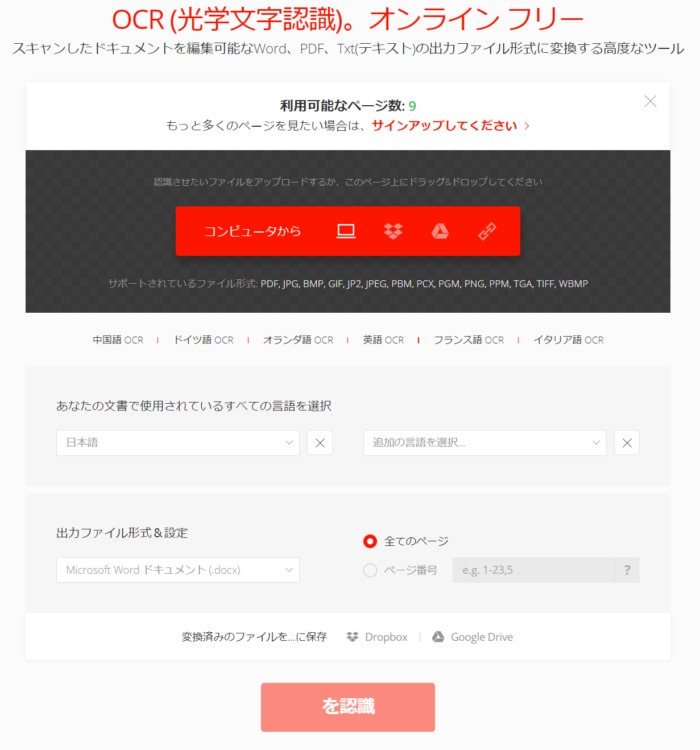
変換するデータを選択した後、「を認識」というボタンをクリックします。おそらく、自動翻訳機能を用いているため、変な日本語になっていると思われます。変換が終了すると、青塗りで「ダウンロード」という表示が出てきますので、そちらからダウンロードをしましょう。
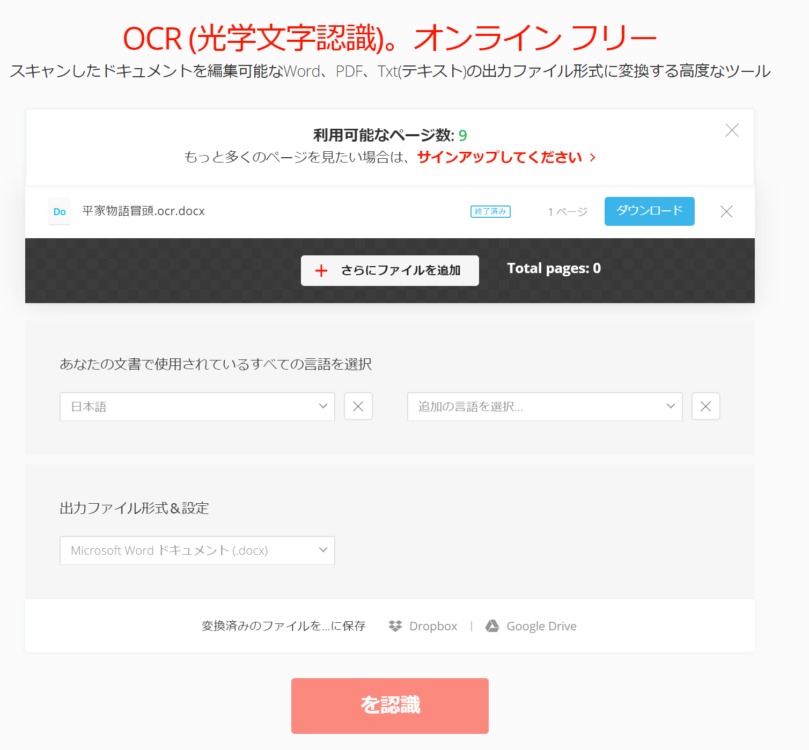
convertioで変換したwordファイルを開いたところ、次のようになっていました。ミスは「唯春の夢のごとし。」の「ご」の部分だけでした。このことから、文字の認識能力という観点では、Convertioに軍配があがりそうですね。まぁ、サンプル数が1つなので、何とも言えませんけどね。

Convertioの注意点
- 最大ファイルサイズは100MBです。
- 10ページまで変換可能
最大ファイルサイズは大きいものの10ページまでしか同時に変換できないので、あまり意味は無いかもしれません。残念ながら、変換可能ページ数の回復に必要な時間は公式サイトに表記がありませんでした。後日分かりましたら、追記します。
まとめ
- 画像PDFファイルをどうやってテキスト化するの?
Free Online OCRやConvertioなどのオンラインOCR(光学文字認識)により、テキスト化することが出来ます。 - どっちのサイトがおすすめなのか?
性能面ではFree Online OCRもConvertioも大差ありません。どちらのサイトも実用性があります。しかし、無料版の場合と変換ページ数に制限があるので、両方活用することをおすすめします。そうすれば、同時に25ページ分のPDFを変換することが出来るので。
最近のコメント